[머신러닝/딥러닝] Stacking Ensemble 스태킹 앙상블
오늘은 머신러닝과 딥러닝에서 자주 사용되는 스태킹 앙상블 알고리즘에 대해 공부해보자
머신러닝에서 많이 사용되는 이 알고리즘의 개념은 간단하게 다음과 같다.
1. 개념
앙상블(ensemble)기법은 크게 보팅(voting), 배깅(bagging), 부스팅(boosting)으로 나뉘며, 추가적으로는 스태킹(stacking) 방법이 있다.
이 기법은 여러 알고리즘을 서로 결합하여 예측 결과를 더 높게 도출한다는 점에서 배깅과 부스팅과 공통점이 있다.
하지만 가장 큰 차이점은, 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 점이다.
즉, 개별 알고리즘의 모델들로 예측결과를 각각 도출한 뒤, 그 예측결과들을 다시모아서 train dataset을 만들어, 별도의 ML알고리즘으로 최종학습을 수행하고 최종 예측을 수행하는 방식이다.
즉, 여러개의 개별 모델들이 필요하고
마지막 최종 메타 모델이 필요하다.
핵심은 여러 개별모델의 예측데이터를 각각 스태킹 형태로 결합하여
최종모 메타 모델의 학습용 feature dataset과 테스트 feature dataset을 만드는 것.
[ 간단한 모식도 ]

[ 구체적인 모식도 ]

2. 적용 예시

위 4개의 예측모델로 예측한 결과이다.

그리고 최종 메타모델을 선정하여 이들의 데이터셋으로 학습시킨다.

최종 메타 모델은 로지스틱 회귀이고 이를 학습시켜 예측 정확도를 측정하였다.
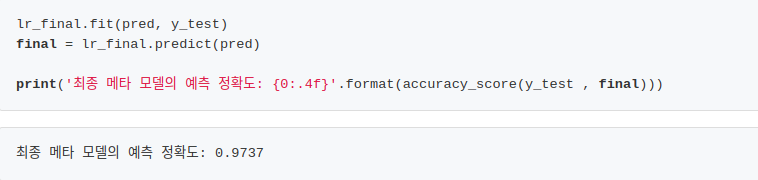
정확도가 더 높아졌다!
추후, 이 스태킹 앙상블을 이용하여 진행하고 있는 playground 캐글 경진대회에서 적용한 코드를 포스팅하도록하겠다.
< My Github Link >
https://github.com/seokjunHwang
seokjunHwang - Overview
Hwangseokjun. seokjunHwang has 4 repositories available. Follow their code on GitHub.
github.com