오늘은 저번시간에 다뤘던 모델들을 한번에 학습시키도록 코드를 리팩토링 해보았다.
이전에 올린 포스트 중에서,
머신러닝 회귀예측 프로젝트를 다뤘었다.
https://jayindustry.tistory.com/27
[머신러닝/딥러닝] 스태킹 앙상블(Stacking Ensemble) 설명 및 실전코드
오늘은 지난시간에 포스팅한 스태킹 앙상블의 실전에 직접 사용했던 코드를 공유하고 설명해보겠다. < 지난 포스팅 : 스태킹 앙상블 개념 및 예시 > https://jayindustry.tistory.com/24 [ML/DL] Stacking Ensemble
jayindustry.tistory.com
이 프로젝트에는 6가지의 모델들을 각각 학습시킨 코드가 있는데
다시보니,
코드가 너무 지저분하다 ...
내 코드에 중복된 코드가 너무 많고,
변수, 리스트 등의 저장공간을 너무 많이 잡아먹는것이 보였다.
그래서 코드의 가독성과 저장공간을 고려해, 1차 정제를 해보았다.
이 포스트에서는 각 모델들을 학습시키는 코드를 정제하였다.
[ 수정 전 코드 ]
모델 6가지를 각각 학습시켰다.


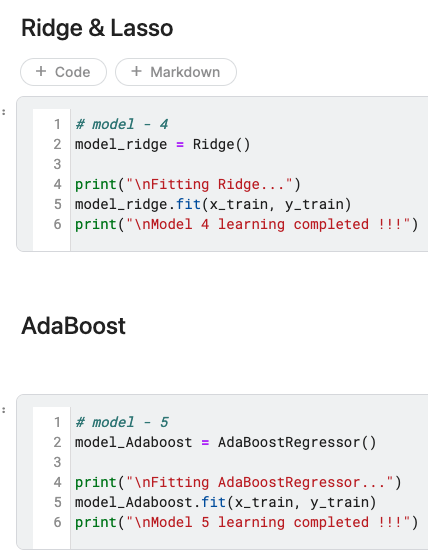

그렇다. 너무길다
처음코드짤땐, "음 이런모델들이 있었지?"
하면서 하나씩 생각없이 추가했는데
결과를 놓고보니 스크롤내리는데 손가락이 아팠다...
[ 수정 후 코드 ]

[ 개념추가 enumerate ]
여기서 순번을 매기는 idx는
enumerate를 사용하여 (0, 'apple'), (1, 'banana'), (2, 'cherry')와 같은 튜플을 생성하며,
여기서는 for 루프에서 각 튜플은 idx와 (model_name, model)로 언패킹된다.
인덱스 시작 값을 변경하고 싶을 때
start 파라미터 사용할 수 있다.
enumerate(model_dict.items(), start = 1)
이런식으로 말이다.
[ 결과 !!! ]
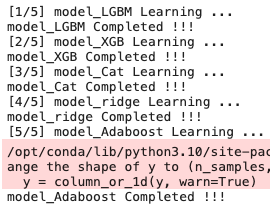

이렇게 학습중일때 어떤 모델들이 학습중인지 프린트되고,
결과물로는 { 내가 지정한 모델명 : 실제 학습에 사용된 모델명 }
이렇게 딕셔너리 형태로 한번에 저장하였다.
처음엔 이 리스트들을 각각 리스트로 저장했는데
이후에 앙상블 할 때 이 모델들을 불러오면서
쓸데없이 많은 변수와 리스트 저장공간을 쓰게 된다는 허점이 보였다.
그래서 아예 1차 정제시, 딕셔너리형태로 다 넣어버렸다.
이를 통해 낭비되는 저장공간을 아낄 수 있었다.
추후, 이 녀석들을 검증하고 앙상블하는데 쓰이는 코드 또한 리펙토링하여 포스팅할 예정이다 !
'Python&Dev > Refactoring Code' 카테고리의 다른 글
| [머신러닝] 회귀예측 5 - 모델학습/성능평가코드 : 리팩토링 2 (0) | 2023.09.16 |
|---|