오늘은 저번 피쳐엔지니어링을 이어서 진행해보았다.
저번에 했던 피쳐엔지니어링은 타겟밸류와 상관관계가 높게 나온,
즉, MI score가 0.5 이상인 피쳐들만 가지고
나머지는 drop처리 한 뒤, 모델학습을 진행하였다.
결과는 오히려 좋지 않게 나왔는데,
너무 많은 피쳐들을 제거함이 원인이지 않나 싶다.
< 저번 포스팅 >
https://jayindustry.tistory.com/34
[머신러닝/딥러닝] 피쳐엔지니어링 실전코드
저번에 포스팅한 예측프로젝트의 스태킹앙상블을 이어서, 오늘은 피쳐엔지니어링과 그 결과를 가져왔다. 지난 포스팅 : 스태킹 앙상블 실전코드 https://jayindustry.tistory.com/27 [머신러닝/딥러닝] 스
jayindustry.tistory.com
오늘은 색다르게 접근해보았다.
데이터셋의 모든 피쳐들(컬럼들)을 뉴메리컬(연속된 수치)와 카테고리컬(분류,0or1)로 나누어 진행해보았다.

그리고 추가로 with_children이라는 컬럼도 추가하였는데,
데이터셋에 고객의 총자녀수와 집에 머물고있는 자녀수가 있길래
그 둘의 차이를 이용하여 함께 '마트에 온 자녀수'라는 의미의 컬럼값들을 만들었다.
[ 피쳐엔지니어링 2차 시도 ]
- with_children 추가
- 뉴메리컬 컬럼들 제거 ( MI score가 카테고리컬 컬럼들이 높았기 때문 )
- 높은 상관관계를 가지는 뉴메리컬 컬럼들은 살림
- 제거 : 타겟밸류(cost)와 전혀 관련없는 id, prepared_food와 완전히 같은 값인 salad_bar 제거

살아남은 컬럼들...
똑같이 5개의 모델로 학습시키고
스태킹앙상블 기법으로 최종 모델인 LightGBM으로 학습시켰다.
< 전체 코드는 github 참고 >
[ 결과 ]
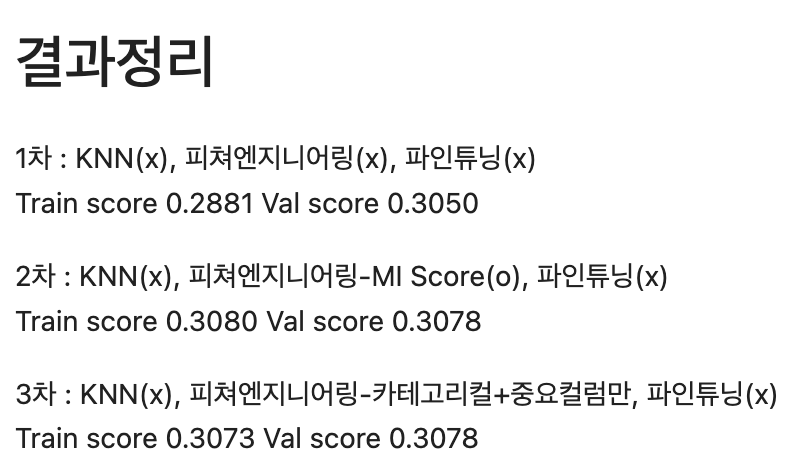
2차가 이전에 했던 점수이고
3차가 이번에 검증한 점수이다.
Train점수가 아주약간 좋아졌으나 이건 똑같다고 봐야한다.
성능향상이 되지않았다.
여전히 너무 많은 피쳐들을 제거한 것이 아닌가 하는 생각이 들었다.
[ 고민해보기 ]
다시 보니 뉴메리컬에 카테고리컬 컬럼들도 포함시킨것같다.
아이들 수, 차량 수 같은 컬럼들은 카테고리컬 컬럼으로 포함시켜야했다.
그리고 여전히 학습에 사용된 컬럼 수가 너무 적다.
좀 더 추가하고 제거할 컬럼들을 조정해봐야겠다.
그리고 확실히 하이퍼파라미터 튜닝이 없으니 오차점수가 별 차이가 없는 것 같다.
파인튜닝의 중요성을 실감했다.
다음 포스팅에서 다룰 업데이트내용은 아래와 같다.
추가적인 피쳐엔지니어링 : 시설 합계 추가, 카테고리컬에 정수형(사람 수 ,차량 수)추가
간단한 파인튜닝
'AI > ML DL' 카테고리의 다른 글
| [머신러닝/딥러닝] 회귀예측 9 - 하이퍼파라미터튜닝(optuna,kfold)/옵튜나,교차검증 (0) | 2023.09.25 |
|---|---|
| [머신러닝/딥러닝] 회귀예측 8 - 3차 피쳐엔지니어링 (0) | 2023.09.22 |
| [머신러닝/딥러닝] 머신러닝으로 비트코인 가격 예측하기(텐서플로우) (0) | 2023.09.20 |
| [머신러닝/딥러닝] 회귀예측 6 - 1차 피쳐엔지니어링 실전코드 (0) | 2023.09.19 |
| [머신러닝/딥러닝] 회귀예측 3 - 스태킹 앙상블(Stacking Ensemble) 설명 및 실전코드 (0) | 2023.09.11 |