오늘은 회귀모델 프로젝트의 피쳐엔지니어링 과정 중, 다중공선성을 판별하는 VIF값에 대해 다루어보겠다.
[ 개념 ]
1. 다중공선성이란?
회귀분석을 할때, 변수(feature)들로 하여금 타겟밸류를 예측한다.
변수들은 일반적으로 독립변수들로 선정한다.
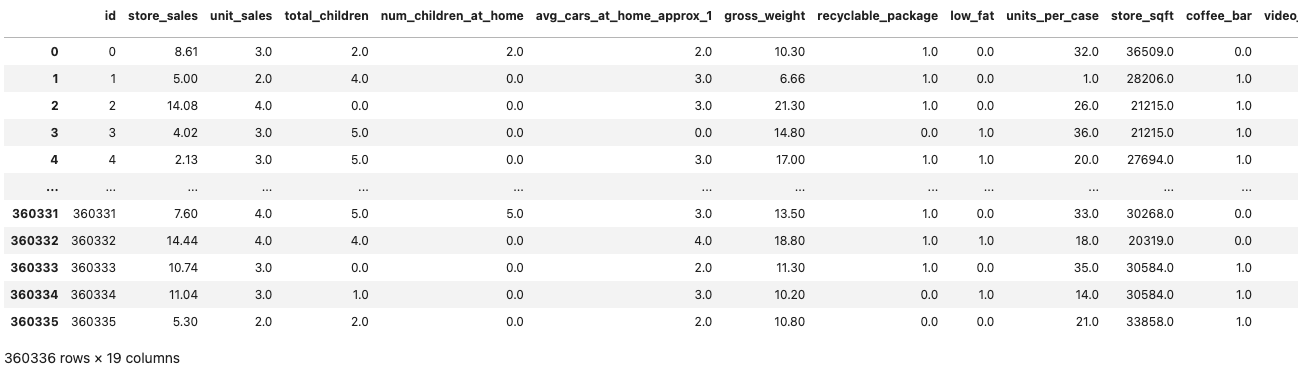
이처럼 다양한 컬럼(피쳐)들의 수치를 토대로 타겟밸류(여기선 "cost")를 예측하는 것이다.

이 때, 독립변수(피쳐)간에 상관관계가 매우 강하면 오히려 예측을 방해하는 문제가 나타난다.
이를 다중공선성문제(Multicollinearity)라고 한다.
예를들어, 축구선수의 연봉협상을 예측해야할 때,
즉, 연봉을 타겟밸류(종속변수)로 뒀을 때,
독립변수1을 훈련량, 독립변수2를 비만도라고 둔다면
독립변수1이 증가할 때, 타겟밸류도 증가할테고,
독립변수2가 감소할 때, 타겟밸류가 증가할 것이다.
이 때, 독립변수1,2는 서로 상관관계가 크다고 판단할 수도 있다.
왜냐면 훈련량이 많을 때, 비만이 된다는 것은 일반적인 상황에서 잘 일어나지 않기 때문이다.
즉, 1이 영향을 미치는 범위가 2에도 동시에 영향을 끼치게 될 것이고, 예측을 방해하게 될 것이다.
이러한 다중공선성을 진단하는 방법 중 하나가 바로 VIF수치이다.
2. VIF (Variance Inflation Factor)
- 분산 팽창 인수.
- 다중회귀분석에서 독립변수가 다중 공산성(Multicollnearity)의 문제를 갖고 있는지 판단하는 기준.
- 주로 10보다 크면 그 독립변수는 다중공산성이 있다.
더욱 엄격하게 기준을 잡으면 VIF수치가 5이상이면 다중공선성 문제가 있다고 하는 경우도 있다.
VIF를 계산하는 식도 있지만, 우리는 이걸 어떻게 우리 코드로 적용하느냐가 중요할 것이다.
바로 코드로 넘어가보자 !
[ 코드 ]
회귀예측 모델 - 스태킹앙상블 프로젝트를 진행하며 사용했던 코드이다.
먼저 다중공선성 확인을 위해 데이터셋의 EDA를 진행하였다.
< 상관관계 EDA로 다중공선성 찾기 >
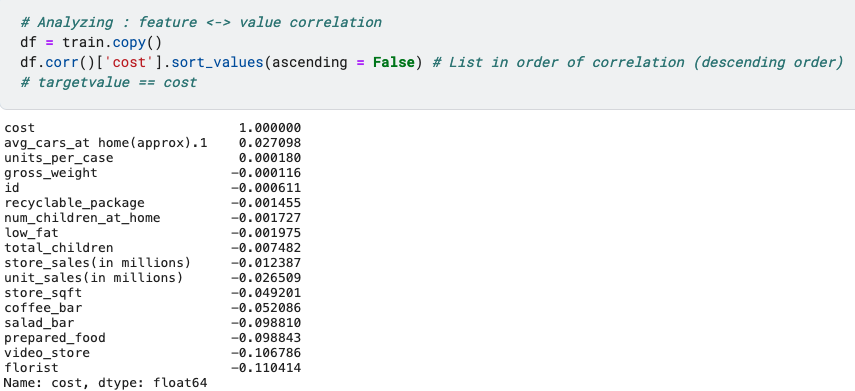
corr()함수를 사용하여, 타겟밸류 "cost"와의 상관관계를 내림차순으로 정리하였다.
이 값의 절댓값이 높을수록 상대적으로 높은 상관관계를 지니고있다고 생각할 수 있다.
위 데이터셋은 전체적으로 비교적 낮은 상관관계를 가지고 있다.
그리고 아래는 피쳐들간의 상관관계를 히트맵으로 그려보았다.


찾았다 요놈들!
salad_bar와 prepared_food가 서로 상관관계다 1.0이다.
즉, 값들이 완전 똑같다는 말이다.
그래서 추후, 피쳐엔지니어링에서
상대적으로 MI Score(타겟밸류와 상관중요도가 높은 점수)가 높은 prepared_food를 살리고
salad_bar컬럼은 drop시켰다.
이렇게 상관관계를 EDA하여 다중공선성을 확인하는 방법이 있고,
다음은 위에서 언급한 VIF수치로 찾는 방법이다.
< VIF >


피쳐에 위처럼 공백이나 (, . 이런 특수문자들이 있으면 에러가 발생하여,
특수문자가 있는 컬럼들을 임시로 변경해주고
다른 변수로 저장해주었다.
-> "train_2"
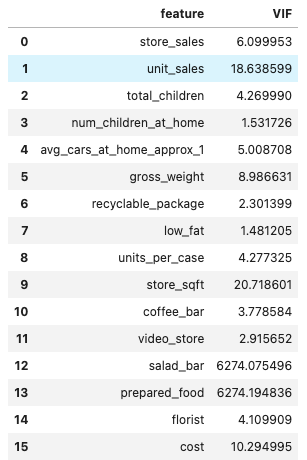
예상대로 salad_bar와 prepared_food의 vif수치가 하늘로 승천하는 것이 보인다.
확실히 다중공선성 문제가 있어보인다.
나머지 10을 넘어가는 다른 피쳐들 또한, 회귀예측 모델을 학습시키면서
하나씩 지워나가며 실험해볼 예정이다.
'AI > ML DL' 카테고리의 다른 글
| [머신러닝/딥러닝] 회귀예측 16 (최종제출) - Cat,XGB,LGBM,스태킹앙상블 (0) | 2023.10.10 |
|---|---|
| [머신러닝/딥러닝] 회귀예측 15 - 스태킹앙상블3, Cat,XGB,LGBM,KNN (1) | 2023.10.09 |
| [머신러닝/딥러닝] 회귀예측 13 - 스태킹앙상블2, KNN 하이퍼파라미터 튜닝 (2) | 2023.10.02 |
| [머신러닝/딥러닝] 회귀예측 12 - 스태킹앙상블 (0) | 2023.10.01 |
| [머신러닝/딥러닝] 머신러닝으로 비트코인 가격예측하기 (0) | 2023.09.30 |