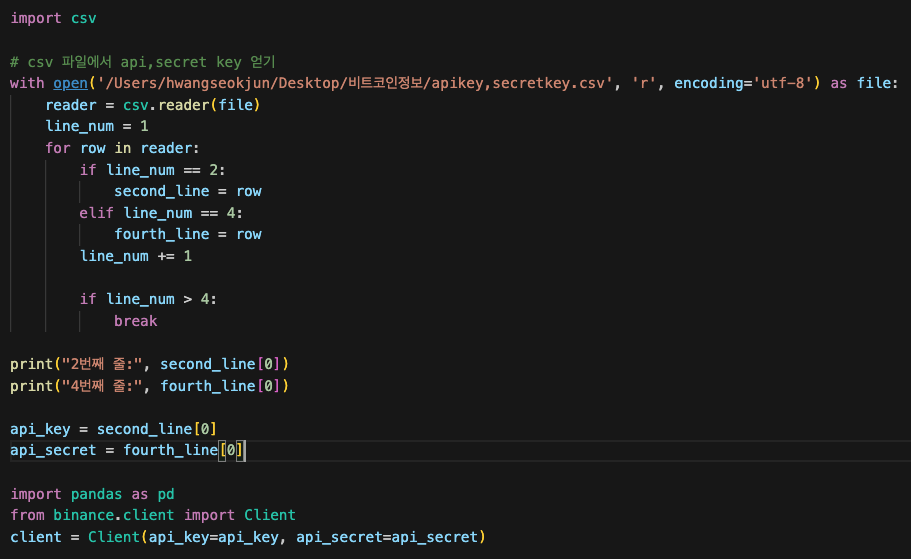
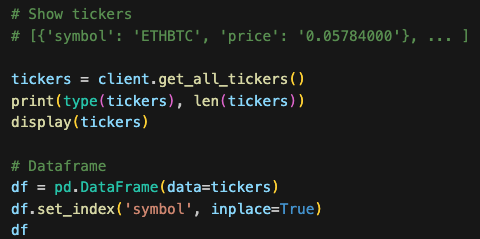
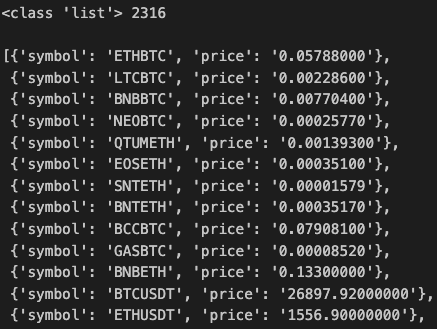
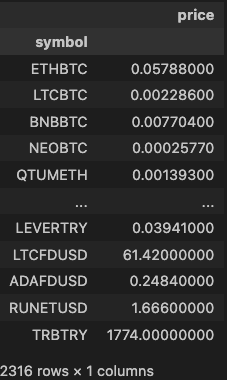
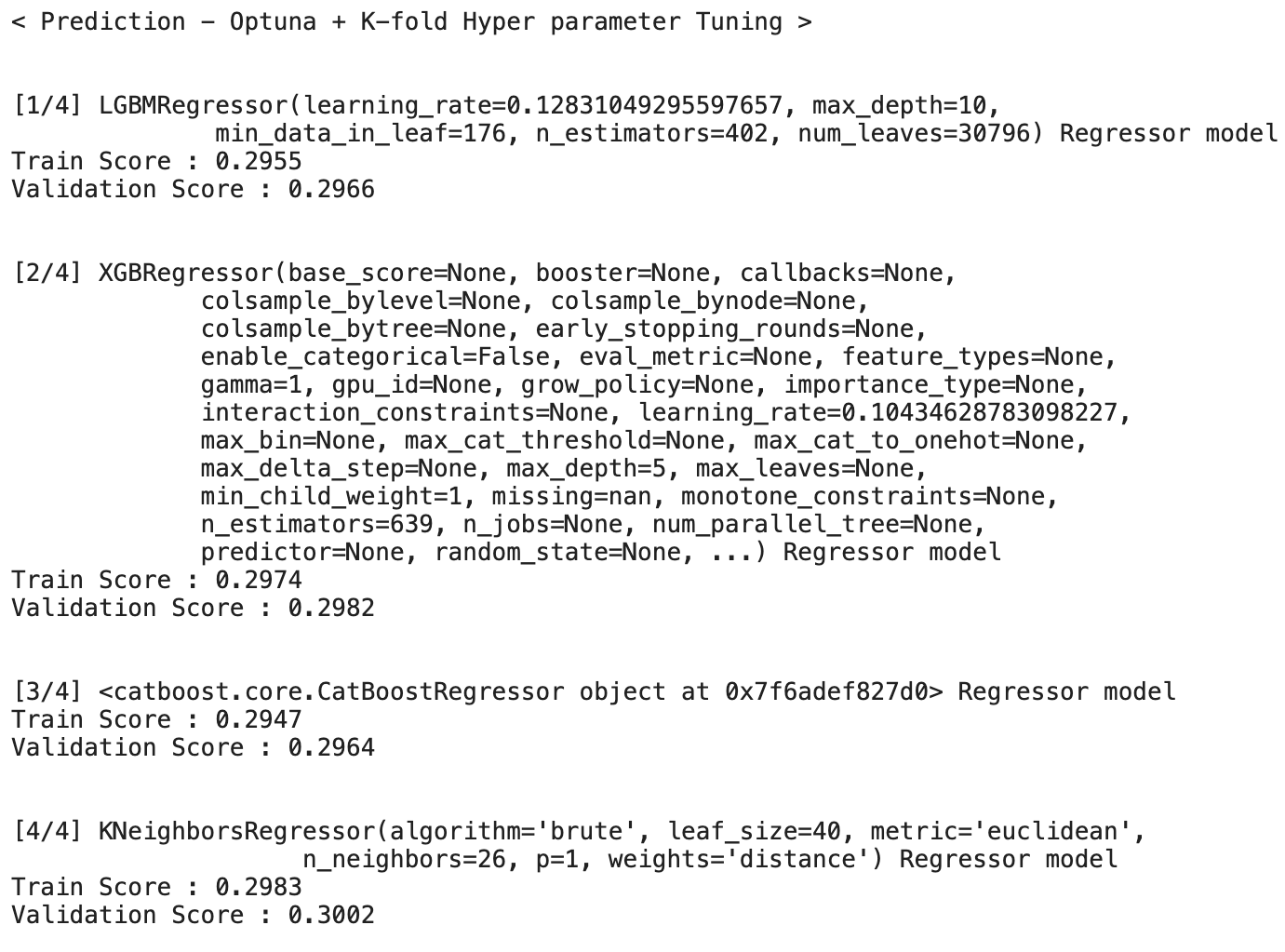
오늘은 퀀트와 관련된 많은 기업들에서의 주요업무인 HFT의 개념과 특징에 대해 심도있게 알아보았다.
[ 개념 ]
High - Frequency Trading : 고빈도 매매
수학적 모델을 활용하여 시장에서 이익을 얻기위한 차익거래전략을 세우고 한 초 이하 단위의 알고리즘 트레이딩 형태의 매매를 의미한다.
소위 '밀리초단타'를 의미하는 것 같다.
일반적으로 고성능 컴퓨터로 프로그램을 사용하여 빠른속도로 거래를 실행하고, 알고리즘은 시장 데이터를 분석하고 몇 분의 1초 안에 거래를 실행하도록 설계되어있다. 이를 통해, 매우 작은 가격의 차이를 이용하여 대량의 거래에서 이익을 얻는것을 목표로 한다.
[ 추가개념 ]
DMA (Direct Market Access)
* 투자자가 주식 및 파생상품 주문 시, 증권사의 주문처리 적정성 점검을 간소화하여 자동으로 거래소에 주문이 전달하는 방법을 의미
-> 즉, 주문 방식이 브로커(증권사)의 실질적 브로커가 주문대행 개입없이 자동으로 거래소에 전달한다.
* 경유하지 않고 다이렉트로 주문하기 때문에 투자자의 경우 주문처리가 유연하고 속도가 향상된다.
* 고객 주문의 기밀이 보장되고, 거래비용이 절감되는 효과가 있다.
* 세계적으로 금융IT가 본격화되면서 뉴욕거래소, 런던거래소, 도쿄거래소 등 60여개 거래소에서 DMA를 허용하고 있 다. 국내에서는 지난해 6월말 기준 증권 및 선물사 50개사가 DMA를 이용한 매매주문 서비스를 고객에게 제공하고 있다.
홈트레이딩시스템(HTS)
* 증권사를 거쳐 주문이 체결되는 시스템 -> DMA과는 다른 개념
[ HFT 특징 ]
* 고성능 컴퓨터로 매우 짧은 시간안에 대용량의 트랜잭션을 발생시키므로, 이 안에 시장상황을 분석하고 이에 맞추어 주문을 하기 위한 복잡한 알고리즘을 필요로 한다.
* 방대한 양의 시장데이터를 처리하고 밀리초 단위로 거래를 실행한다.
* 정교한 알고리즘은 HFT의 중요한 구성요소이다. 변화하는 시장 상황에 지속적으로 적응하기 위해서는 머신러닝 기술이 융합되어야 한다.
* 일반적으로 HFT는 높은 회전율과 높은 주문/체결 비율을 보인다.
* 시장에 유동성을 공급하고 작은 매수-매도호가 간의 차이(Bid-Ask Spread)들을 단숨에 제거한다.
-> 즉, HFT로 인해 Bid-Ask Spread는 증가하게 된다.
* HFT로 좋은 성과를 내는 기업에는 Tower Research, Citadle LLC, Virtu Financial 사 등이 있다.
* 경쟁업체보다 빠른 속도로 거래를 수행하고 금융시장에서 경쟁 우위를 확보하기 위해서 고속 데이터 피드 및 낮은 지연시간의 거래플랫폼과 같은 최첨단 기술에 많은 투자가 필요하다.
[ HFT 장점 ]
HFT의 주요 장점은 빠른 속도로 거래를 수행할 수 있다.
이를 통해 작은 가격 변동의 차익을 이용하여 대량의 거래에서 이익을 창출한다.
시장의 유동성을 제공할 수 있으며, 다른 시장 참여자들의 거래비용을 줄이는 데 도움이 될 수 있다.
탁월한 알고리즘 개발에 성공한다면 변화하는 시장에 적합하게 대응이 가능하다.
[ HFT 리스크 ]
HFT알고리즘은 매우 복잡하며 결함이나 오류에 취약할 수 있다.
또한 HFT가 작동하는 속도는 규제기관이 모니터링하고 제어하는 것을 어렵게 할 수 있다.
[ 시장에 미치는 영향 ]
금융 시장에서 시장의 유동성을 증가시키고 매수-매도호가 간의 차이(Bid-Ask Spread)를 감소시킨 공로를 인정받았다.
한편, 시장의 변동성을 크게 만들고, 시장이 불안정한 시기에 이를 더욱 악화시키는 역할을 할 수 있다.
[ 생각 정리 ]
HFT가 뭔지 자세히 알아보지 않고 이것을 도입하여 개인프로젝트를 해봐야겠다고 생각했던 내가 부끄러웠다.
고성능컴퓨터로 복잡한 알고리즘을 사용한 밀리초단타라니..
하지만 밀리초까진 아니더라도 파이썬으로 나만의 전략을 만들어, 초단타로 간단히 구현해볼 수 있을 것 같다.
초단타로 자동매매봇을 만들어, "이런식으로 돌아가는구나.." 하는 전체적인 파이프라인을 몸소 익혀보려고 한다.
'Python&Dev > 퀀트' 카테고리의 다른 글
| [금융공부] 블록체인 시장에서 꼭! 알아야할 주요키워드 - 2 (1) | 2023.12.05 |
|---|---|
| [금융공부] 블록체인 시장에서 꼭! 알아야할 주요키워드 - 1 (0) | 2023.12.04 |
| [트레이딩] 바이낸스거래소 잔고조회~선물,현물거래 (1) | 2023.10.17 |
| [트레이딩] 바이낸스 거래소 라이브러리 사용하기 (0) | 2023.10.15 |